Custom Prometheus Metrics for Apps Running in Kubernetes

Kubernetes solves the application availability management problem through the liveness and readiness probes. Now, how about application performance? Prometheus gives us the capability to instrument the application with the Client API. We can use the API to define the custom metrics to monitor the performance of the application.
In this paper, I will explore the following
- Develop the custom metrics with Prometheus Client API on a toy app
- Deploy the app into Kubernetes (IBM Cloud Private)
- Configure Prometheus in Kubernetes to scrape the metrics
- Present the result in Grafana dashboard. Especially explore the dashboard for multiple replicas of the pod.
1. An App with Custom Prometheus Metrics
As a sample, I use the Prometheus Golang Client API to provide some custom metrics for a hello world web application. The HTTP service is being instrumented with three metrics,
- Total transaction till now, implemented as a Prometheus Counter.
- Currently active client, as a Prometheus Gauge.
- Response time distribution, as a Prometheus Histogram.
The code is attached as below,
I wrap three Prometheus metrics’ into a struct. The InitPrometheusHttpMetric() function initialize metrics with a prefix (or called as a namespace) so that the metrics won’t conflict with others. The TransactionTotal is created as a vector so that different labels such as handler and HTTP status can be segregated. The response time requires a float array for the predefined buckets.
The Prometheus client API provides the HTTP middleware. So instead of we reinvent the wheel, we just wrap our business logic, the HTTP handler, with the Prometheus different type of middlewares. This is what the function WrapHandler()does. It takes a type of http.HandlerFunc, wraps the three custom metrics implementer and return a http.handler for setting the route.
The main handler of the sample app just parses the URL query parameter and sleeps enough to simulate the latency of the service.
The main() function is nothing special.
Compile the code, test run it with some random curl command to populate the Prometheus metrics
$ curl localhost:8080/service?cost=0.2
Time spend for this request: 0.20Then, check the metrics by accessing the URL and grepping only the prefix of “myapp”. We have the custom metrics returned,
$ curl localhost:8080/metrics | grep myapp# HELP myapp_client_connected Number of active client connections
# TYPE myapp_client_connected gauge
myapp_client_connected 0.0
# HELP myapp_requests_total total HTTP requests processed
# TYPE myapp_requests_total counter
myapp_requests_total{code="200",method="get"} 1.0
# HELP myapp_response_time Histogram of response time for handler
# TYPE myapp_response_time histogram
myapp_response_time_bucket{handler="myhandler",method="get",le="0.0"} 0.0
myapp_response_time_bucket{handler="myhandler",method="get",le="5.0"} 1.0
myapp_response_time_bucket{handler="myhandler",method="get",le="10.0"} 1.0
myapp_response_time_bucket{handler="myhandler",method="get",le="15.0"} 1.0
myapp_response_time_bucket{handler="myhandler",method="get",le="20.0"} 1.0
myapp_response_time_bucket{handler="myhandler",method="get",le="25.0"} 1.0
myapp_response_time_bucket{handler="myhandler",method="get",le="30.0"} 1.0
myapp_response_time_bucket{handler="myhandler",method="get",le="35.0"} 1.0
myapp_response_time_bucket{handler="myhandler",method="get",le="40.0"} 1.0
myapp_response_time_bucket{handler="myhandler",method="get",le="45.0"} 1.0
myapp_response_time_bucket{handler="myhandler",method="get",le="50.0"} 1.0
myapp_response_time_bucket{handler="myhandler",method="get",le="55.0"} 1.0
myapp_response_time_bucket{handler="myhandler",method="get",le="60.0"} 1.0
myapp_response_time_bucket{handler="myhandler",method="get",le="65.0"} 1.0
myapp_response_time_bucket{handler="myhandler",method="get",le="70.0"} 1.0
myapp_response_time_bucket{handler="myhandler",method="get",le="75.0"} 1.0
myapp_response_time_bucket{handler="myhandler",method="get",le="80.0"} 1.0
myapp_response_time_bucket{handler="myhandler",method="get",le="85.0"} 1.0
myapp_response_time_bucket{handler="myhandler",method="get",le="90.0"} 1.0
myapp_response_time_bucket{handler="myhandler",method="get",le="95.0"} 1.0
myapp_response_time_bucket{handler="myhandler",method="get",le="+Inf"} 1.0
myapp_response_time_sum{handler="myhandler",method="get"} 0.2000114
myapp_response_time_count{handler="myhandler",method="get"} 1.0
2. Deploy into Kubernetes
Use the multi-stage build Dockerfile to build the docker image.
FROM golang:alpine AS builder
RUN apk update && apk add --no-cache git
COPY src $GOPATH/src/zhiminwen/hpasimulator
WORKDIR $GOPATH/src/zhiminwen/hpasimulator
RUN go get -d -v
RUN go build -o /tmp/simulator *.goFROM alpine
RUN addgroup -S appgroup && adduser -S appuser -G appgroup && mkdir -p /app
COPY --from=builder /tmp/simulator /app
RUN chmod a+rx /app/simulatorUSER appuser
WORKDIR /app
ENV LISTENING_PORT 8080CMD ["./simulator"]
Build and push the image into Docker hub.
Deploy it into Kubernetes (IBM Cloud Private 3.1.1) with the following deployment and service object.
---
apiVersion: v1
kind: Service
metadata:
name: hpa-sim
labels:
app: hpa-sim
spec:
type: NodePort
ports:
- port: 80
targetPort: 8080
protocol: TCP
name: http
selector:
app: hpa-sim
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: hpa-sim
labels:
app: hpa-sim
spec:
replicas: 1
selector:
matchLabels:
app: hpa-sim
template:
metadata:
labels:
app: hpa-sim
spec:
containers:
- name: hpa-sim
image: zhiminwen/hpa-sim:v1
imagePullPolicy: IfNotPresent
env:
- name: LISTENING_PORT
value: "8080"Monitor the pods are running and NodePort can be accessed.
3. Scrape Metrics from Prometheus
Prometheus using the pull method to bring in the metrics. We need to configure Prometheus to scrape the app for the custom metrics. This is achieved by updating the Prometheus config YAML file.
In the IBM Cloud Private (ICP), the config file is a ConfigMap Kubernetes object. You can get it with the command,
kubectl -n kube-system get cm monitoring-prometheus -o jsonpath="{ .data.prometheus\\.yml }" > prom.yamlModify the prom.yaml file by appending the following, (notice the ident, it suppose to be indented at the 2nd tab/spaces)
- job_name: hpa-sim
scrape_interval: 10s kubernetes_sd_configs:
- role: pod relabel_configs:
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: k8s_namespace
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: k8s_pod_name
- source_labels: [__address__]
action: replace
regex: ([^:]+)(?::\d+)?
replacement: ${1}:8080
target_label: __address__
- source_labels: [__meta_kubernetes_pod_label_app]
action: keep
regex: hpa-sim
In fact, there is a couple of ways to scrape the custom metrics. The first one is to use the default “kubernetes-pods” job which will scape the pod that has the annotation of
- prometheus.io/scrape: true for enabling the scraping
- prometheus.io/path: If the metrics path is not `/metrics` override this.
- prometheus.io/port: Specify the non-default port other than 9090
I am not using this approach because I want to have more control over the scraping job on the frequency and labeling. So I create a dedicate job for my custom metrics.
In terms of the target, one way is to use a static config such as
static_configs:
- targets:
- "hpa-sim.default:80"Since Prometheus is running inside the cluster, it can reach the app using its service name. However, the scraping will be managed by the load balancing mechanism of the K8s service. If there are multiple pods running, not all the pods are scrapped.
Instead, we have to use the dynamic discovery feature for Kubenetes in Prometheus. Set the role for kubernetes_sd_configs as “pod”. So the scrape will target all the Kubernetes pods that match the following criteria,
- source_labels: [__meta_kubernetes_pod_label_app]
action: keep
regex: hpa-simThis means Prometheus will ignore all the pods that don’t regex match to “hpa-sim” for the label of “app”. Effectively, it only scrapes the pods that labeled with “app=hpa-sim”.
In the meantime, before the actual scraping, we relabel the __address__ to let it point to the container port for the handler, port 8080.
Lastly, we assign two extra labels for the Prometheus metrics namely the namespace and the pod name instead of setting those labels inside the code.
With these explanations, we can delete the old configMap and create it again to achieve the effect of updating.
kubectl -n kube-system delete cm monitoring-prometheuskubectl -n kube-system create cm monitoring-prometheus --from-
file=prometheus.yml=prom.yaml
Access the /services through the NodePort to allow the metrics to be instrumented.
curl http://192.168.64.244:30543/service?cost=0.2Login to the ICP console with the user and credentials, then access the Prometheus console with the URL of https://192.168.64.244:8443/prometheus Type the name of the custom metrics, hit Execute, you can then see the metrics value as shown below.

4. Present the Metrics on Grafana Dashboard
Let's scale the pods to 3 first.
kubectl scale deploy hpa-sim --replicas=3Metrics of CPU and Memory
First, we build the dashboard for the overall computing resource utilization.
Prometheus Client API provides Golang instrument out of the box with a Counter type metric process_cpu_seconds_total As it is the default metric, for the custom dashboard specific to our app, we have to filter with the right label with the regex, shown as below,
process_cpu_seconds_total{k8s_pod_name=~"hpa-sim-.*"}
Since its a Counter, the value will always grow. What we are interested in is how much it grows when the load is there. Therefore we apply the irate function to get the increase rate. The irate function works on a time period, so we need to get the time range vector with “[30s]”
irate(process_cpu_seconds_total{k8s_pod_name=~"hpa-sim-.*"}[30s])
This gives us three lines on the dashboard if there are multiple pods running. Let's aggregate it with the avg function,
avg(irate(process_cpu_seconds_total{k8s_pod_name=~”hpa-sim-.*”}[30s]))
The final query shown above enables us to draw the CPU utilization panel. The cosmetic details such as legend, axis are ignored here.
For Memory, the query is
avg(process_resident_memory_bytes{k8s_pod_name=~”hpa-sim-.*”})
The metric process_resident_memory_bytes is a type of Gauge which may increase or decrease. We simply average it across all the matching pods.
The resource panel is then shown below,
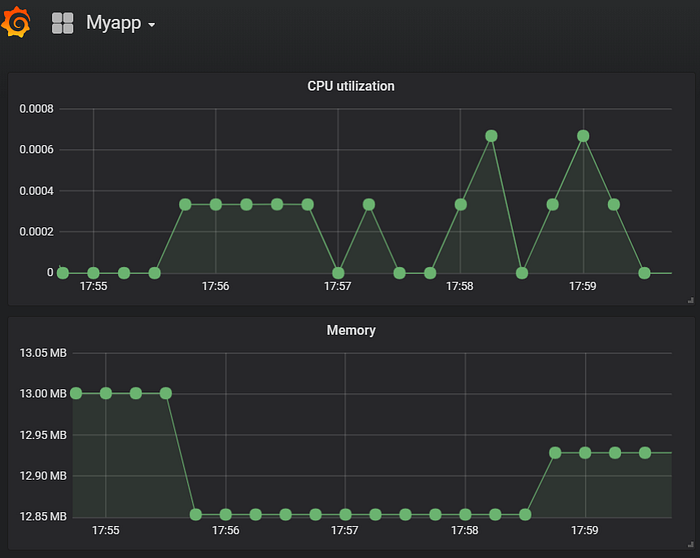
Metric of Inflight Status
Since we have the in-flight active connection metric myapp_client_connected, We display it in the panel of “Active Connection per Pod” by simply using myapp_client_connectedas the query. Meantime, we sum it up sum(myapp_client_connected)and show it in Singlestat panel. The result is below,
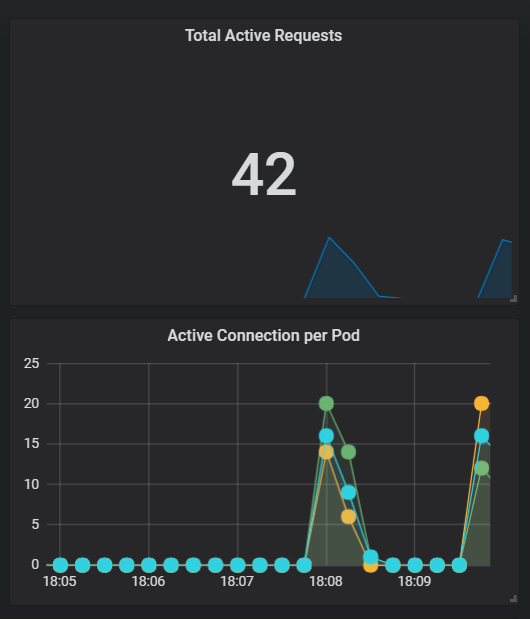
Response Time Distribution
We use the Heatmap panel to draw the distribution of response time.
Set the Axes/Dataformat/Format as “Time series buckets”. The data expected is in Histogram format. For each bucket (identified by the “le” label) there is a value (the count of appearance in this bucket) for it. Use the Prometheus web console, examine the metric from a particular pod shown as below.
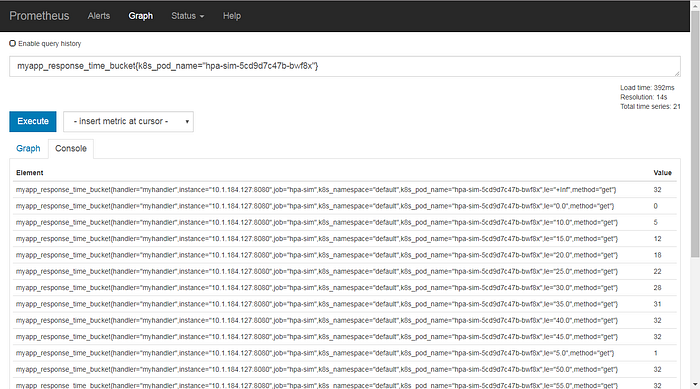
When we have multiple pods running, we need to sum up the value in the same buckets to have the correct Histogram data. Use sum by function to achieve it,
sum(myapp_response_time_bucket{handler=”myhandler”}) by (le)
The resulting heat map is displayed as below,
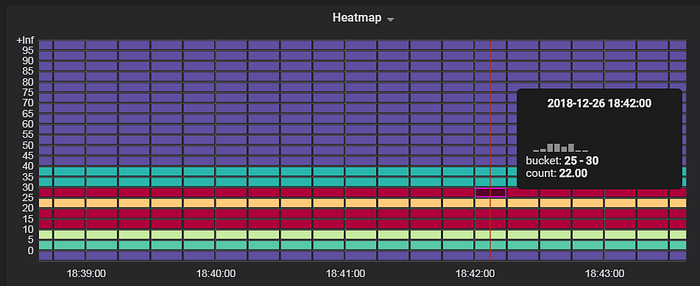
This is the end of this exploration.
Tips: The prometheus web console is very useful to debug your query by showing the data in the table format.
Update: Check out the next paper on how to use these custom metric to perform scale out of pods.
